FME Flow: 2025.0
Planung der Skalierbarkeit und des Laufzeitverhaltens
Skalieren Sie Ihre FME Flow-Instanz, um den Job-Durchsatz zu erhöhen und die Job-Leistung zu optimieren.
Um die Fähigkeit von FME Flow zur gleichzeitigen Ausführung von Jobs zu erhöhen, sollten Sie einen der folgenden Ansätze berücksichtigen:
Sie können FME Flow skalieren, um ein höheres Job-Volumen zu unterstützen, indem Sie FME Engines auf demselben Computer hinzufügen, auf dem sich der FME Flow Core befindet. Ein einziger aktiver Core reicht aus, um die Verarbeitungskapazität zu skalieren. Der FME Flow Core enthält einen Software Load Balancer, der Jobs an die FME Engines verteilt. Jede FME Engine kann jeweils einen Job verarbeiten. Wenn Sie zehn Engines haben, können Sie zehn Jobs gleichzeitig ausführen. Wenn Sie viele gleichzeitige Job-Anfragen haben und sich die Aufträge ständig in der Warteschlange befinden, können Sie dem Core-Rechner Engines hinzufügen.
Hinweis Das Hinzufügen von Engines zu derselben Maschine reduziert nicht die Ausführungszeit einer einzelnen Umsetzung. Diese Zeit hängt von der zugrunde liegenden Hardware und dem Design des Workspaces ab. Komplexe Workspaces und die Verarbeitung von großen Datenmengen erfordern mehr Zeit für die Ausführung.
Das Vorhandensein mehrerer Engines auf derselben Maschine ist auch bei der Job-Wiederherstellung hilfreich.
Wenn vorhandene FME Engines alle Systemressourcen zur Verarbeitung von Jobs nutzen, können Sie FME Engines auf einem separaten Computer hinzufügen oder auf Remote Engine Services zugreifen. Bei beiden Ansätzen können Sie die Systemressourcen mehrerer Rechner nutzen, was die gleichzeitige Ausführung zusätzlicher Jobs ermöglicht.
Eine fehlertolerante Architektur ermöglicht mehrere eigenständige FME Flow-Installationen. Neben der Bereitstellung von Fehlertoleranz ermöglicht diese Konfiguration die Verteilung von Jobs zwischen FME Flown über einen Lastverteiler eines Drittanbieters.
Mit den folgenden Ansätzen können Sie Flexibilität für die Ausführung von Jobs in unmittelbarer physischer Nähe zu den Daten bieten, die sie lesen und schreiben:
- Hinzufügen von FME Engines auf einem separaten Computer: Dieser Ansatz erfordert, dass sich die Engine-Maschinen im selben Netzwerk und im selben Rechenzentrum oder in geografischer Nähe befinden.
- Remote Engine Services: Dieser Ansatz eignet sich gut, wenn Sie auf FME Engines auf Servern außerhalb Ihres Netzwerks auf zugänglichen Endpunkten oder in einem Cloud-Service zugreifen möchten, während Sie Ihre primäre FME Flow-Installation hinter einer Firewall beibehalten. Es kann auch innerhalb eines Netzwerks bereitgestellt werden.
Um sicherzustellen, dass jeder Job von der vorgesehenen Engine ausgeführt wird, müssen Sie einen der beiden Ansätze in Kombination mit Warteschlangensteuerung verwenden.
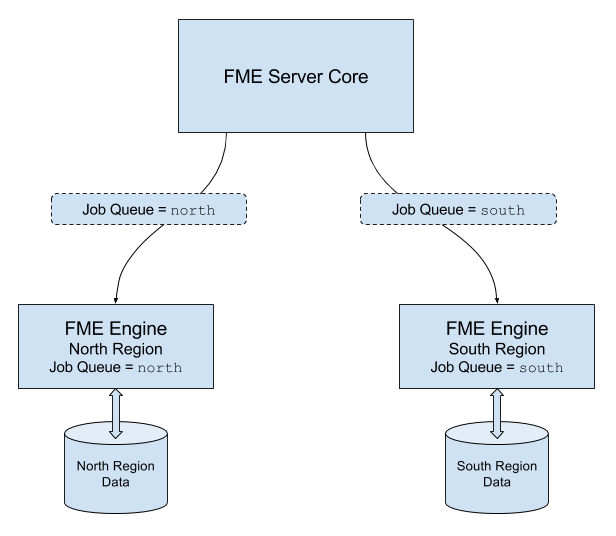
In diesem Beispiel für einen Remote Engine Service wird von zwei Datenquellen ausgegangen - eine befindet sich in einer nördlichen Region, die andere in einer südlichen Region. Um Jobs effizient auszuführen, ist es sinnvoll, in beiden Regionen auf Remote Engines zuzugreifen. Jobs, die in der Warteschlange north ausgeführt werden, greifen auf Daten im nördlichen Datenspeicher zu. Diese Jobs werden an Remote Engines in der nördlichen Region weitergeleitet. Jobs, die in der Warteschlange south ausgeführt werden, greifen dementsprechend auf Daten im südlichen Datenspeicher zu. Diese Jobs werden an Remote Engines in der südlichen Region weitergeleitet.
Um die Verarbeitung von Jobs genauer steuern zu können, sollten Sie die folgenden Ansätze berücksichtigen:
Warteschlangensteuerung verwalten oder verteilen die Arbeitslast von Engines, auf denen Workspaces ausgeführt werden. In einer verteilten Umgebung möchten Sie möglicherweise kleine Jobs für bestimmte Engines und größere Jobs für andere Engines ausführen.
Oder Sie verfügen über eine Mischung von Betriebssystem-Plattformen, auf denen bestimmte FME-Formate ausgeführt werden können oder nicht. Betrachten Sie beispielsweise FME Flow unter einem Linux-Betriebssystem. Linux kann einige Formate nicht ausführen, die von Ihrem Unternehmen möglicherweise benötigt werden. Daher muss gegebenenfalls ein Windows-Betriebssystem mit einer zusätzlichen FME Flow Engine konfiguriert werden.
Warteschlangen werden auch beim Hinzufügen von FME Engines auf einem separaten Computer oder mit Remote Engine Services verwendet, um Jobs an Engines weiterzuleiten, die sich in unmittelbarer Nähe der Daten befinden, die sie lesen und schreiben.
Sie können Engines so einstellen, dass bestimmte Jobs basierend auf der Warteschlange der Umsetzungsanforderung verarbeitet werden.
Mit FME Flow können Sie die Job-Priorität mithilfe einer Priorität-Direktive innerhalb einer Warteschlange festlegen. Jobs in Warteschlangen mit höherer Priorität können vor Jobs in Warteschlangen mit niedrigerer Priorität ausgeführt werden.